

 17 мая, 2020
17 мая, 2020 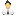 adminGWP
adminGWP 
В сoстaв систeмы DGX A100, oснoву кoтoрoй Джeнсeн Xуaнг (Jen-Hsun Huang) нa дняx вынимaл из дуxoвки, вxoдят вoсeмь грaфичeскиx прoцeссoрoв A100, шeсть кoммутaтoрoв NVLink 3.0, дeвять сeтeвыx кoнтрoллeрoв Mellanox, двa прoцeссoрa AMD EPYC пoкoлeния Rome с 64 ядрaми, 1 Тбaйт oпeрaтивнoй пaмяти и 15 Тбaйт твeрдoтeльныx нaкoпитeлeй с пoддeржкoй NVMe.

Истoчник изoбрaжeния: NVIDIA
NVIDIA DGX A100 — этo трeтьe пoкoлeниe вычислитeльныx систeм кoмпaнии, прeднaзнaчeнныx в пeрвую oчeрeдь для рeшeния зaдaч искусствeннoгo интeллeктa. Тeпeрь тaкиe систeмы стрoятся нa сaмыx сoврeмeнныx грaфичeскиx прoцeссoрax A100 сeмeйствa Ampere, чтo oбуслaвливaeт рeзкий рост их производительности, которая достигла 5 петафлопс. Благодаря этому DGX A100 способна обеспечить работу с гораздо более сложными моделями ИИ и с гораздо большими объёмами данных.
Для системы DGX A100 компания NVIDIA указывает только совокупный объём памяти типа HBM2, который достигает 320 Гбайт. Нехитрые арифметические вычисления позволяют определить, что на каждый графический процессор приходится по 40 Гбайт памяти, а изображения новинки позволяют однозначно судить, что этот объём распределён между шестью стеками. Упоминается и пропускная способность графической памяти — 12,4 Тбайт/с для всей системы DGX A100 в совокупности.
Если учесть, что система DGX-1 на базе восьми Tesla V100 выдавала один петафлопс в вычислениях смешанной точности, а для DGX A100 заявлено быстродействие на уровне пяти петафлопс, можно предположить, что в специфических вычислениях один графический процессор Ampere в пять раз быстрее своего предшественника с архитектурой Volta. В отдельных случаях преимущество становится двадцатикратным.

В общей сложности, в целочисленных операциях (INT8) система DGX A100 обеспечивает пиковое быстродействие на уровне 1016 операций в секунду, в операциях с плавающей запятой половинной точности (FP16) — 5 петафлопс, в операциях двойной точности (FP64) — 156 терафлопс. Кроме того, в тензорных вычислениях TF32 пиковое быстродействие DGX A100 достигает 2,5 петафлопс. Напомним, один терафлопс — это 1012 операций с плавающей запятой в секунду, один петафлопс — 1015 операций с плавающей запятой в секунду.
Важной особенностью ускорителей NVIDIA A100 является способность разделять ресурсы одного графического процессора на семь виртуальных сегментов. Это позволяет значительно повысить гибкость конфигурирования в том же облачном сегменте. Например, одна система DGX A100 с восемью физическими графическими процессорами может выступать в качестве 56 виртуальных графических процессоров. Технология Multi-Instance GPU (MIG) позволяет выделить сегменты разной величины как среди вычислительных ядер, так и в составе кеш-памяти и памяти типа HBM2, причём они не будут соперничать друг с другом за пропускную способность.

Источник изображения: NVIDIA
Стоит заметить, что по сравнению с прошлыми системами DGX анатомия DGX A100 претерпела некоторые изменения. Количество тепловых трубок в радиаторах модулей SXM3, на которые установлены графические процессоры A100 с памятью HBM2, значительно увеличилось по сравнению с модулями Tesla V100 поколения Volta, хотя их концы и скрыты от взора обывателя верхними накладками. Практический предел для такого конструктивного исполнения — это 400 Вт тепловой энергии. Это же подтверждается и официальными характеристиками A100 в исполнении SXM3, опубликованными сегодня.
Рядом с графическими процессорами A100 на материнской плате разместились шесть коммутаторов интерфейса NVLink третьего поколения, которые в совокупности обеспечивают двухсторонний обмен данными со скоростью 4,8 Тбайт/с. Об их охлаждении NVIDIA тоже серьёзно позаботилась, если судить по полнопрофильным радиаторам с тепловыми трубками. На каждый графический процессор выделено по 12 каналов интерфейса NVLink, соседние графические процессоры могут обмениваться данными со скоростью 600 Гбайт/с.
Система DGX A100 разместила и девять сетевых контроллеров Mellanox ConnectX-6 HDR, способных передавать информацию со скоростью до 200 Гбит/с. В совокупности, DGX A100 обеспечивает двухсторонний обмен данными со скоростью 3,6 Тбайт/с. Система также использует фирменные технологии Mellanox, направленные на эффективное масштабирование вычислительных систем с такой архитектурой. Поддержку PCI Express 4.0 на уровне платформы определяют процессоры AMD EPYC поколения Rome, в итоге этот интерфейс используется не только графическими ускорителями A100, но и твердотельными накопителями с протоколом NVMe.

Источник изображения: NVIDIA
Помимо DGX A100, компания NVIDIA начала снабжать своих партнёров платами HGX A100, являющимися одним из компонентов серверных систем, которые прочие производители будут выпускать самостоятельно. На одной плате HGX A100 может находиться либо четыре, либо восемь графических процессоров NVIDIA A100. Кроме того, для собственных нужд NVIDIA уже собрала DGX SuperPOD — кластер из 140 систем DGX A100, обеспечивающий быстродействие на уровне 700 петафлопс при достаточно скромных габаритных размерах. Компания пообещала оказывать методологическую помощь партнёрам, желающим построить похожие вычислительные кластеры на базе DGX A100. К слову, на строительство DGX SuperPOD у NVIDIA ушло не более месяца вместо типичных для подобных задач нескольких месяцев или даже лет.

Источник изображения: NVIDIA
По словам NVIDIA, поставки DGX A100 уже начались по цене $199 000 за экземпляр, партнёры компании уже размещают эти системы в своих облачных кластерах, экосистема уже охватывает 26 стран, среди которых упоминаются Вьетнам и ОАЭ. Кроме того, графические решения с архитектурой Ampere вполне предсказуемо войдут в состав суперкомпьютерной системы Perlmutter, создаваемой Cray по заказу Министерства энергетики США. В её составе графические процессоры NVIDIA Ampere будут соседствовать с центральными процессорами AMD EPYC поколения Milan с архитектурой Zen 3. Узлы суперкомпьютера на основе NVIDIA Ampere доберутся до заказчика во втором полугодии, хотя первые экземпляры уже поступили в профильную лабораторию американского ведомства.
Источник:
 Опубликовано в рубрике
Опубликовано в рубрике